GPT-OSS 120B
Pierwszy otwarty model OpenAI od czasu GPT-2 w 2019 roku. GPT-OSS 120B to model reasoning klasy o4-mini — z pełnym chain-of-thought, obsługą narzędzi i konfigurowalnym poziomem rozumowania. Licencja Apache 2.0 bez żadnych ograniczeń komercyjnych.
Architektura Mixture-of-Experts
GPT-OSS 120B to model transformerowy z architekturą MoE, który aktywuje zaledwie 5,1 miliarda parametrów na token z łącznych 117 miliardów. Wykorzystuje naprzemienne warstwy dense i locally banded sparse attention (wzorowane na GPT-3) oraz grouped multi-query attention dla wydajności pamięci. Pozycjonowanie za pomocą Rotary Positional Embedding (RoPE) wspiera kontekst do 128K tokenów.
Model reasoning z chain-of-thought
To nie jest zwykły model generatywny — GPT-OSS 120B myśli krok po kroku przed udzieleniem odpowiedzi. Posiada konfigurowalny poziom rozumowania (low / medium / high), co pozwala balansować między szybkością a dokładnością w zależności od zadania. Na najwyższym poziomie dorównuje zamkniętemu o4-mini OpenAI.
Narzędzia i function calling
Post-training obejmował specjalistyczny etap reinforcement learning ukierunkowany na obsługę narzędzi i zadania agentowe. Model potrafi wywoływać funkcje, używać code interpretera, przeszukiwać źródła danych i generować spójne trajektorie działań przez dziesiątki kroków. Wyniki na TAU-bench (retail) potwierdzają praktyczną użyteczność w scenariuszach obsługi klienta.
Wdrożenie na DGX Spark / ASUS GX10
Dzięki natywnej kwantyzacji MXFP4, pełny model mieści się na pojedynczym GPU 80 GB. Na naszych stacjach DGX Spark i ASUS GX10 ze 128 GB zunifikowanej pamięci model działa komfortowo z zapasem na długie konteksty. Kompatybilny z vLLM, llama.cpp (reference Triton implementation) i frameworkami OpenAI-compatible.
Apache 2.0 — pełna wolność
W odróżnieniu od modeli Meta (Llama License z ograniczeniem 700M MAU), GPT-OSS jest wydany na licencji Apache 2.0 bez jakichkolwiek ograniczeń — pełna swoboda użytku komercyjnego, modyfikacji, dystrybucji i fine-tuningu. To czyni go idealnym fundamentem do budowania dostosowanych rozwiązań dla klientów.
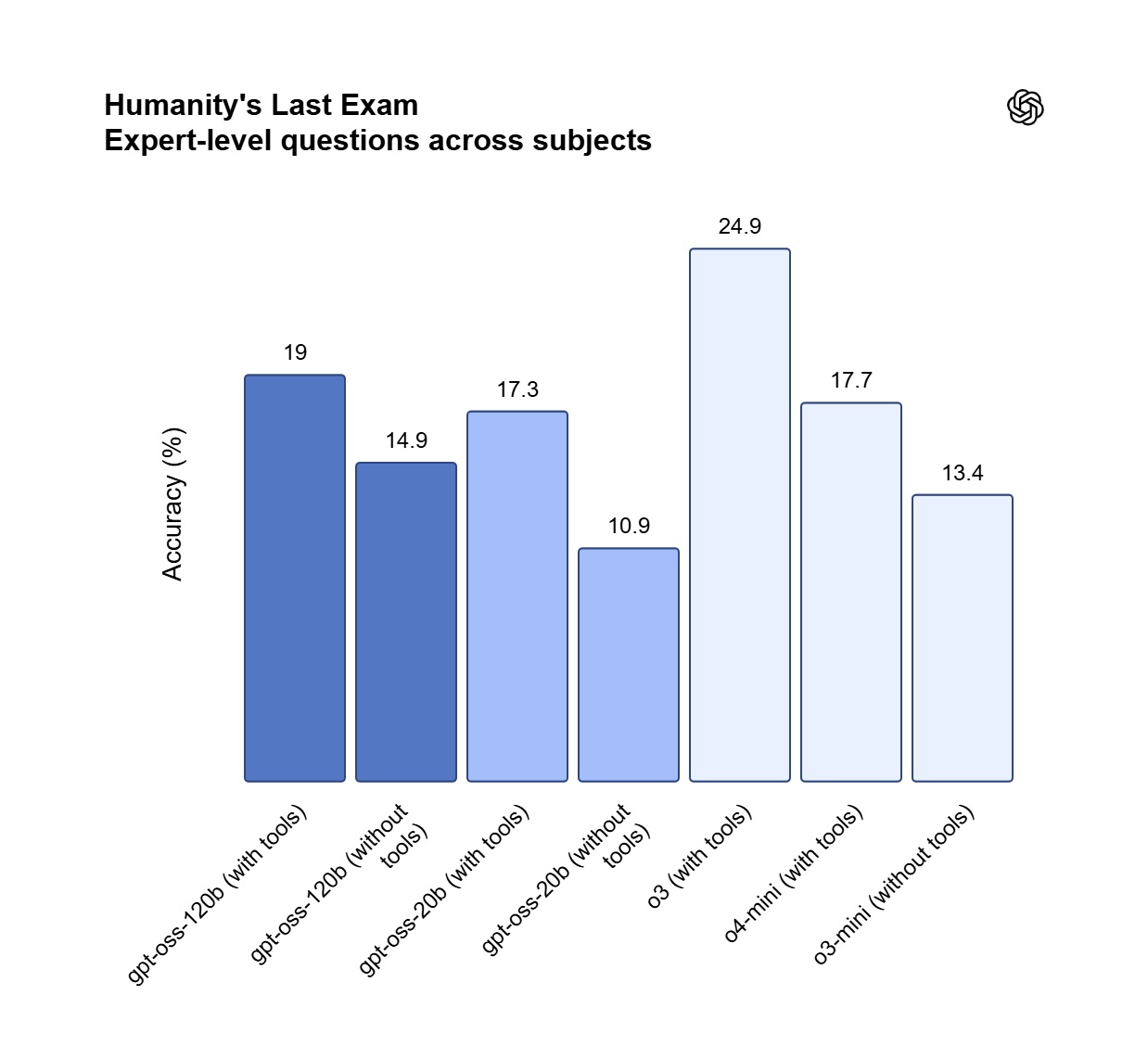
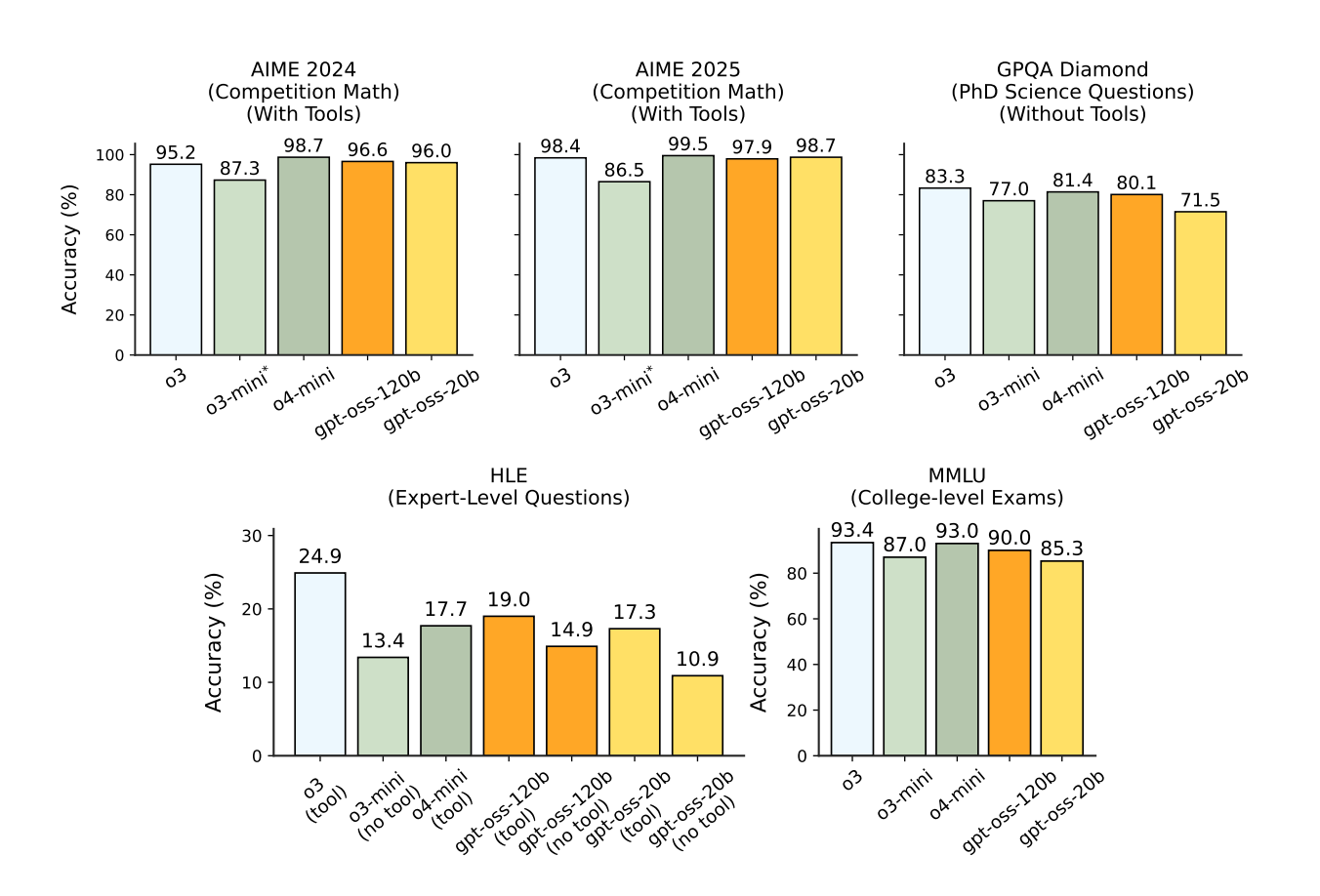
Kluczowe benchmarki
Reasoning: high. Źródło: openai.com, fireworks.ai
Idealny do:
- Zaawansowanego rozumowania i analizy danych (STEM, prawo, finanse)
- Automatyzacji z tool-use — function calling, code interpreter, SQL
- Agentów autonomicznych z wieloetapowym planowaniem
- Fine-tuningu pod specyficzne domeny (Apache 2.0, pełna swoboda)
- Zastępstwa zamkniętych modeli OpenAI — bez opłat per-token, pełna prywatność
GPT-OSS 120B vs. konkurencja
GPT-OSS osiąga near-parity z o4-mini na benchmarkach reasoning (AIME, GPQA). Kluczowa różnica: GPT-OSS działa lokalnie, bez opłat per-token i bez przesyłania danych do chmury. Pełna kontrola nad prywatnością.
GPT-OSS przewyższa DeepSeek R1 na AIME 2025 (97.9% vs ~92%) i MMLU (90% vs 85%). DeepSeek R1 jest modelem dense 671B, więc wymaga znacznie więcej zasobów. GPT-OSS mieści się na jednym GPU.
GPT-OSS wygrywa w reasoning (MMLU 90 vs 80.5, GPQA 80.9 vs 69.8). Scout ma przewagę w multimodalności (tekst+obraz) i 78× dłuższym kontekście (10M vs 128K). Różne nisze — reasoning vs. agent multimodalny.