MiniMax M2.7 — 230B agentowy MoE na klastrze DGX Spark
Self-evolving agent, 94.2 AIME, 78 SWE-bench Verified. Zmierzone in vivo: 33–36 tok/s.
Otwarte modele językowe gotowe do lokalnego wdrożenia na sprzęcie NVIDIA DGX Spark i ASUS GX10 Ascent — 128 GB zunifikowanej pamięci, ~1 PFLOP mocy obliczeniowej.

Największy model, jaki uruchomiliśmy lokalnie: 230B MoE (10B aktywnych), „samodoskonalący się" agent z natywnym tool-callingiem. Na SWE-bench Verified wyprzedza Claude Opus. Serwowany z naszego klastra 2× DGX Spark: 33–36 tok/s, kontekst 131K tokenów.
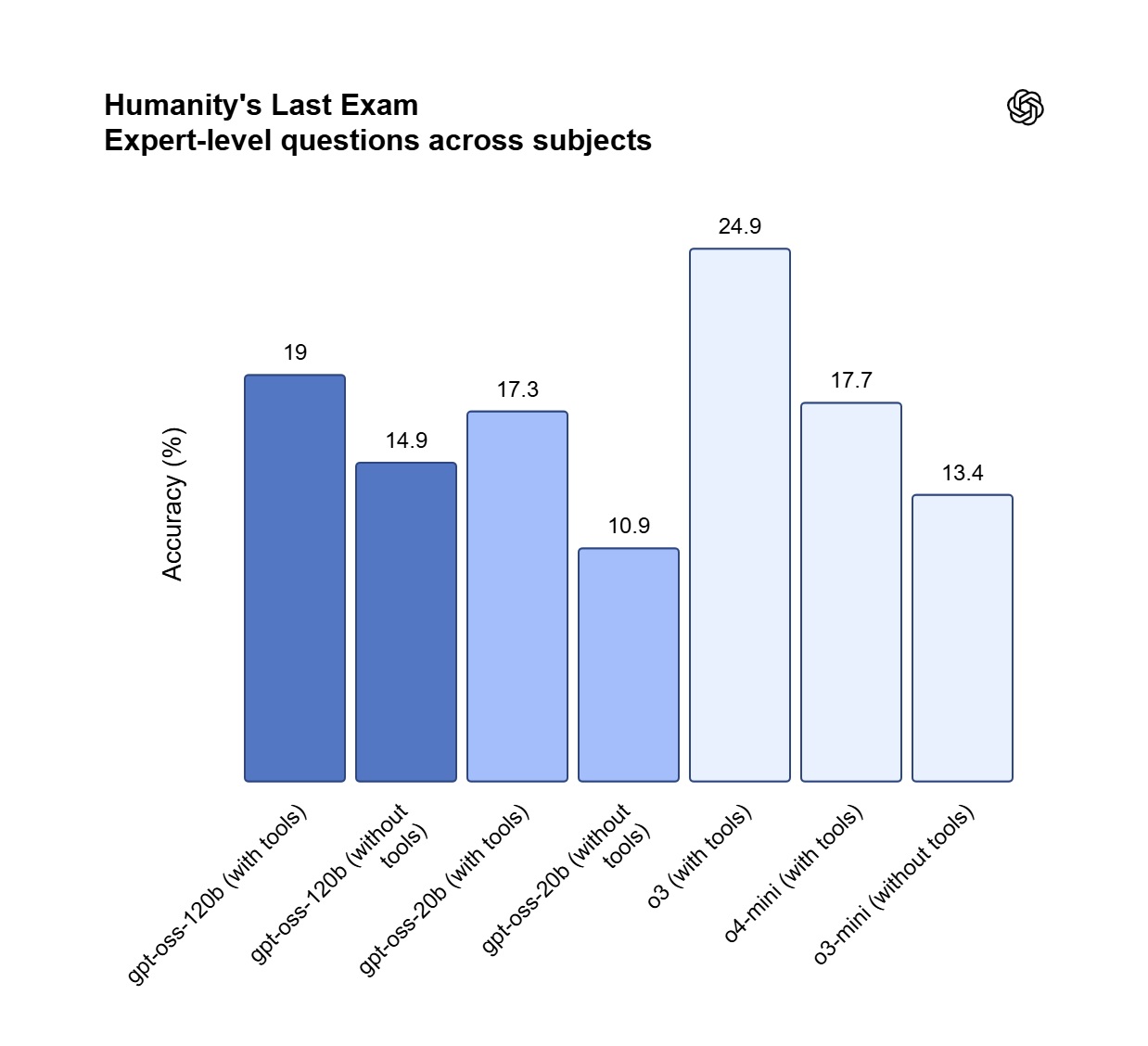
Pierwszy otwarty model OpenAI od czasów GPT-2. Architektura Mixture-of-Experts: 117B parametrów, z czego tylko 5,1B aktywnych na token. Dorównuje o4-mini w benchmarkach rozumowania. Licencja Apache 2.0, natywne chain-of-thought i obsługa narzędzi. Mieści się na pojedynczym GPU 80 GB.
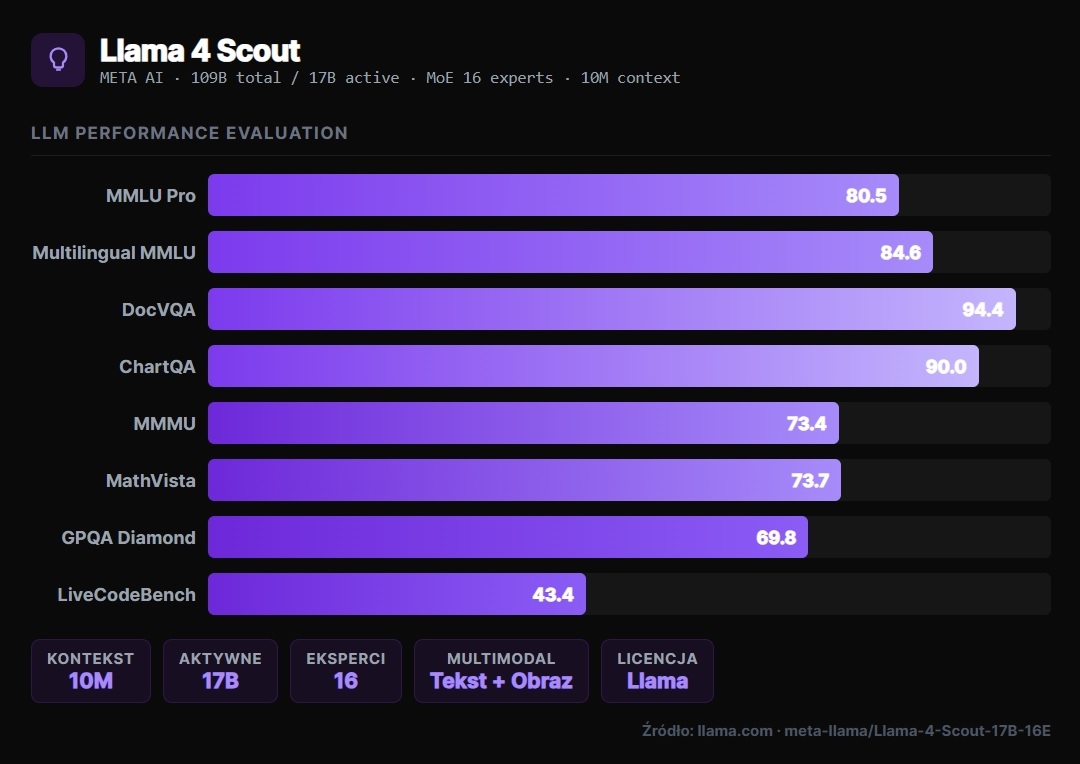
Flagowy model open-source od Meta. Wersja „Scout" zoptymalizowana pod agentów autonomicznych i złożone zadania wieloetapowe. Architektura MoE z potężnym oknem kontekstowym, doskonała obsługa polskiego i wielu języków.
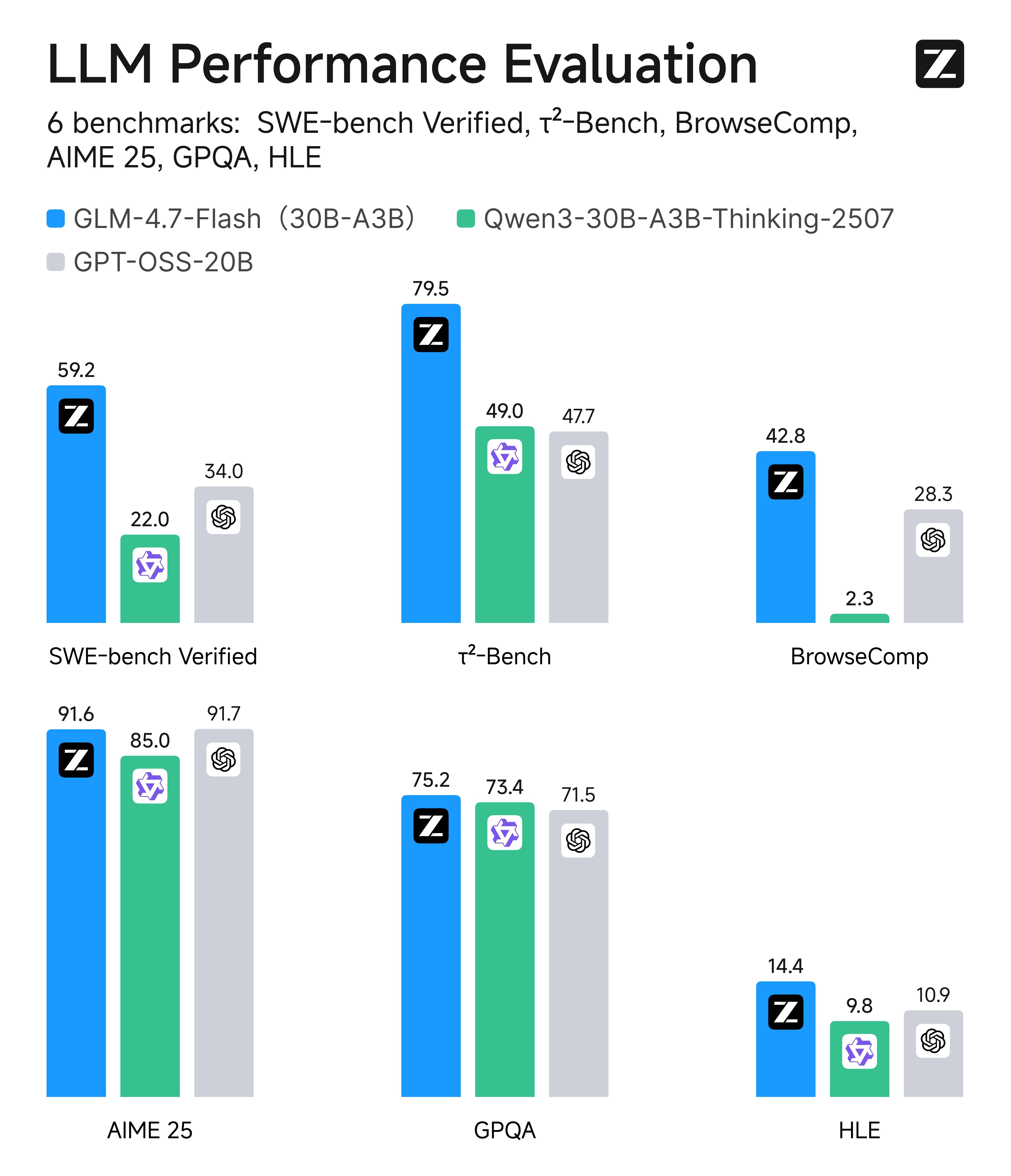
Model typu Mixture-of-Experts od Zhipu AI (30B MoE). Gigantyczne okno kontekstowe 1M tokenów pozwala analizować całe regulaminy i akty prawne jednorazowo. Testowany lokalnie na ASUS GX10 — bezbłędna analiza Ustawy o rynku kryptoaktywów.

Najnowszy model od Google DeepMind (kwiecień 2026), zbudowany na bazie badań Gemini 3. Pozycja #3 wśród otwartych modeli na arenie Arena AI. Multimodalny — przetwarza tekst i obrazy, wbudowany tryb reasoning (thinking mode). Pokonuje Llama 4 w matematyce, kodowaniu i zadaniach agentowych.
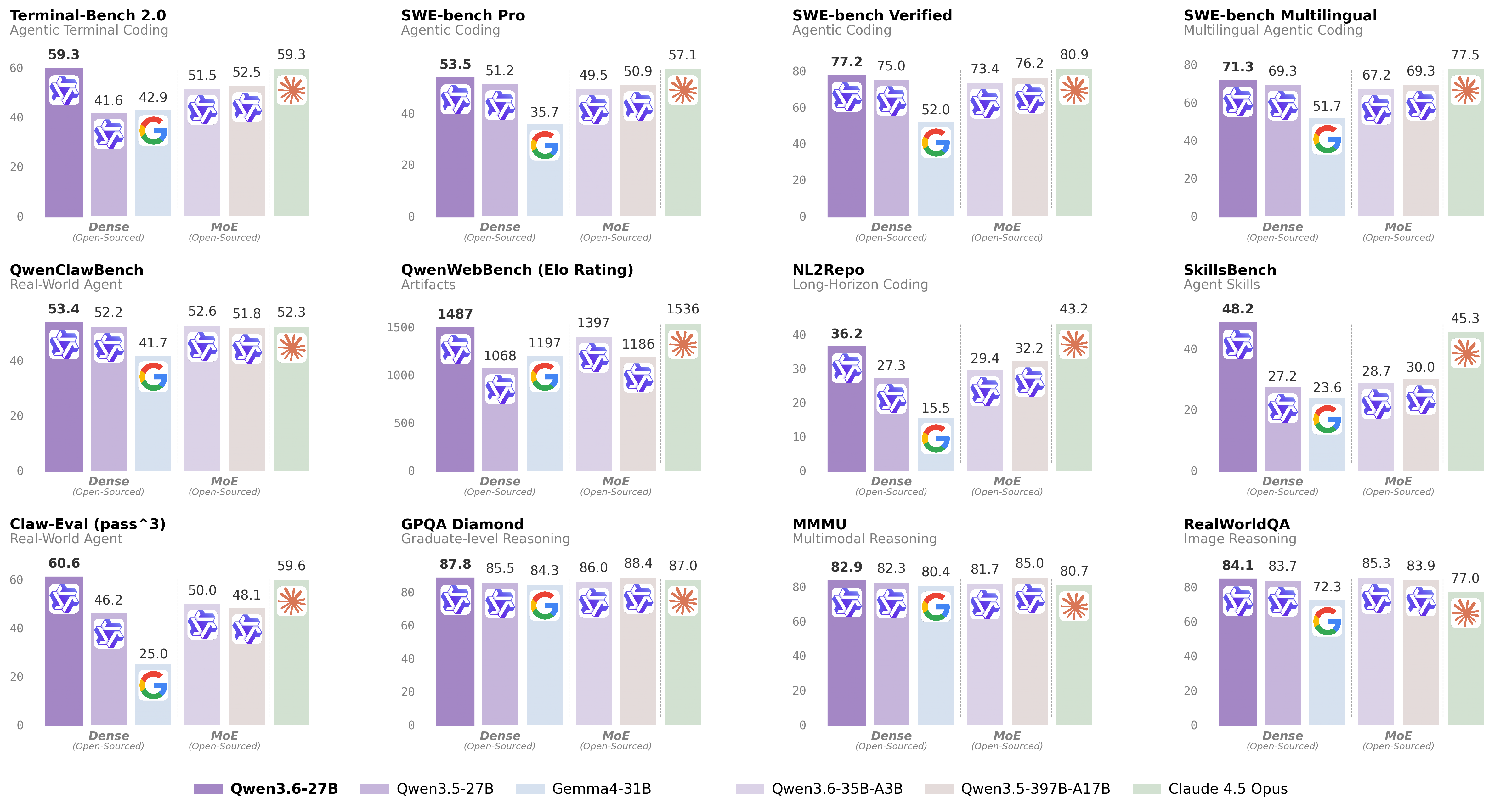
Dwa warianty od Alibaba: 27B (dense) — flagowy coding, przewyższa modele 15× większe w benchmarkach agentowych; 35B-A3B (MoE, 3B aktywnych) — 3-4× szybszy, idealny do RAG i narzędzi. Oba z kontekstem 256K i obsługą multimodalną.
Otwarty model graficzny (9.3B DiT) sterowany ustrukturyzowanym JSON-em: osobna kontrola każdego obiektu, kompozycji i typografii, edycja pojedynczego elementu bez ruszania reszty kadru. Uruchomiony lokalnie na ASUS GX10 (fp8, ~19 GB). Na stronie: demo + konkurs z bonem 2000 zł.
Self-evolving agent, 94.2 AIME, 78 SWE-bench Verified. Zmierzone in vivo: 33–36 tok/s.
Kontrola każdego obiektu w kadrze, bezbłędna typografia. Lokalnie na ASUS GX10.
MoE z reasoning i tool-use. Apache 2.0, mieści się na jednym GPU 80 GB.
Meta AI podnosi poprzeczkę dla modeli open-source.
Testujemy model Zhipu AI na analizie aktów prawnych.
Dense 31B z reasoning i multimodalnością. #3 na arenie open-source, Apache 2.0.
Dwa warianty: 27B dense i 35B-A3B MoE. Kontekst 256K, Apache 2.0.