
Mały gigant
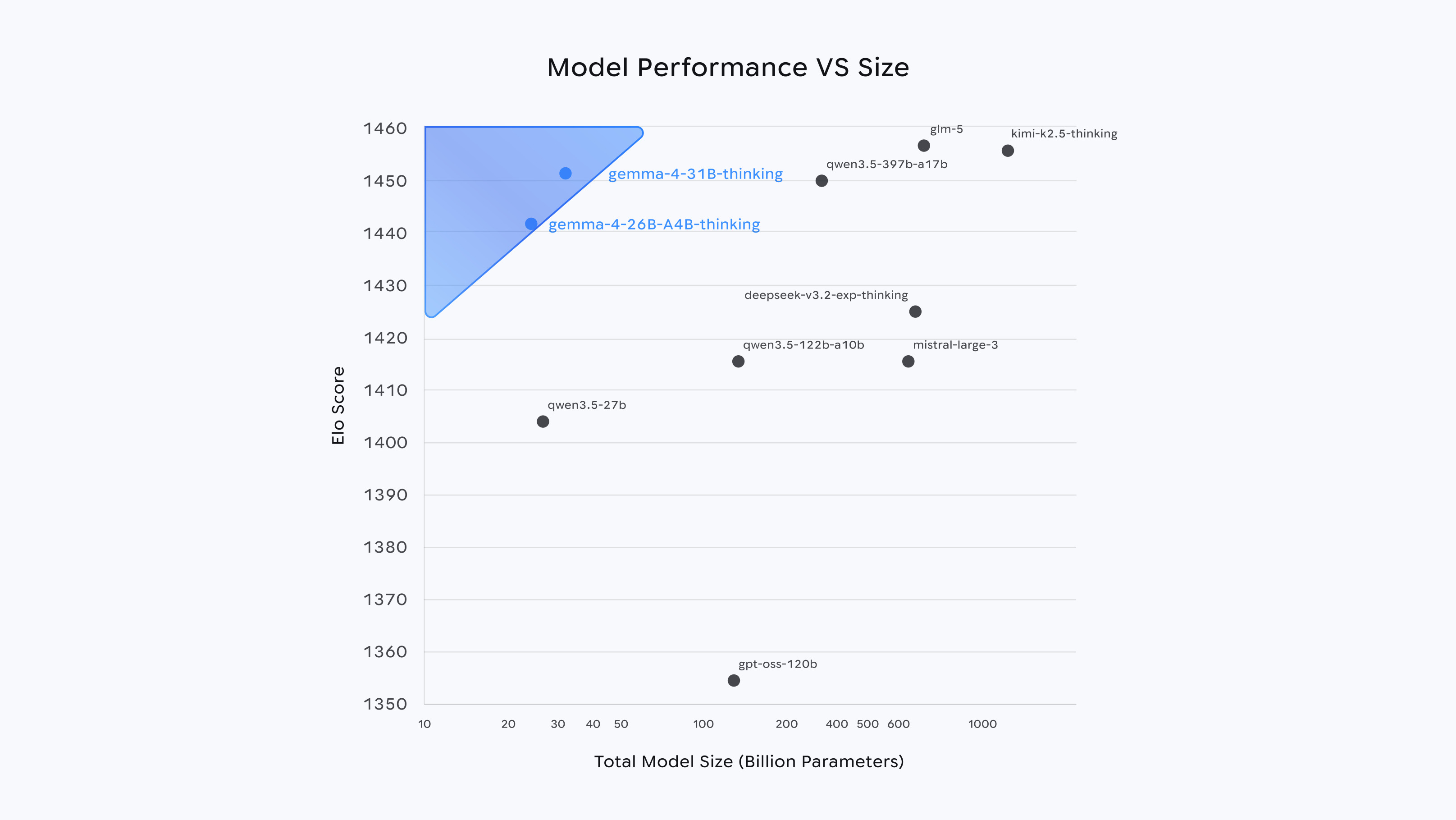
Gemma 4 31B to najnowsze dzieło Google DeepMind, wydane 2 kwietnia 2026. To model dense — wszystkie 30,7 miliarda parametrów pracuje przy każdym tokenie. Żadnego routingu, żadnych śpiących ekspertów. Efekt? Maksymalna jakość na parametr i przewidywalne zachowanie. Na Arena AI zajmuje pozycję #3 wśród wszystkich otwartych modeli z wynikiem ELO 1452 — pokonując modele o łącznej wielkości 200–600 miliardów parametrów, w tym warianty Llama 4, DeepSeek V3.2 i Qwen 3.5.
Skok generacyjny w benchmarkach
Skala poprawy względem Gemma 3 jest bezprecedensowa. Na AIME 2026 (zaawansowana matematyka konkursowa) Gemma 4 osiąga 89.2% — skok z 20.8% w poprzedniej generacji. Codeforces ELO wzrósł z 110 do 2150 — największy jednopokoleniowy skok w historii otwartych modeli. Na MMLU Pro (zaawansowana wiedza akademicka) wynik to 85.2%. To nie jest „dobry model za swoją wielkość" — to model na poziomie frontier, który po prostu jest mniejszy niż konkurencja.
Architektura i Thinking Mode
Model wykorzystuje hybrydowy mechanizm uwagi, który przeplata lokalne sliding-window attention z pełnym global attention, gwarantując że ostatnia warstwa zawsze ma widok na cały kontekst. Pozycjonowanie oparte o Proportional RoPE (p-RoPE) utrzymuje zużycie pamięci w ryzach przy kontekstach do 256K tokenów. Wbudowany tryb reasoning (thinking mode) pozwala modelowi „myśleć" krok po kroku przed odpowiedzią — kluczowe dla złożonych zadań logicznych i matematycznych.
Natywna multimodalność
Gemma 4 31B przetwarza tekst, obrazy i wideo natywnie — nie jest to dodatkowy moduł, ale integralna część architektury. Rozumie wykresy, dokumenty, screenshoty interfejsów, a nawet ręcznie rysowane wireframe'y, które potrafi przekształcić w funkcjonalny kod React/Tailwind. Obsługuje ponad 140 języków z uwzględnieniem kontekstu kulturowego.
Wydajność i efektywność tokenowa
Gemma 4 zużywa do 2,5× mniej tokenów na to samo zadanie w porównaniu do konkurencji. Oznacza to szybszą generację i niższe koszty operacyjne. W kwantyzacji Q4_K_M (sweet spot wydajność/jakość) model zajmuje ~20 GB pamięci. Na naszych stacjach DGX Spark i ASUS GX10 ze 128 GB zunifikowanego RAM-u mieści się z ogromnym zapasem, pozostawiając miejsce na długie konteksty.
Przetestowany z lokalną bazą wektorową (RAG)
Gemma 4 31B przeszła u nas praktyczny benchmark RAG na jednostce GX10: model pracował z lokalną bazą wektorową (AnythingLLM + LanceDB, embedder Qwen3 8B) zbudowaną na zbiorze 510 umów korporacyjnych CUAD, odpowiadając w trybie Query — wyłącznie na podstawie dokumentów, z odsyłaczami do źródeł. Pełny opis konfiguracji i metodologii znajdziesz we wpisie RAG — inteligentne przeszukiwanie dokumentów, a zapis rozmowy z testu — w sekcji Benchmark Transcript poniżej.
Wdrożenie lokalne
Instalacja jednym poleceniem: ollama run gemma4. Kompatybilny z vLLM, llama.cpp, LM Studio i Transformers. API zgodne z formatem OpenAI. Licencja Apache 2.0 bez jakichkolwiek ograniczeń komercyjnych — pełna swoboda fine-tuningu, modyfikacji i redystrybucji.
Benchmarki
Thinking mode. Źródło: blog.google, artificialanalysis.ai
31B pokonuje modele:
Na Arena AI text leaderboard (ELO). Kwiecień 2026.
Specyfikacja
Idealny do:
- Zaawansowanego reasoning (matematyka, logika, STEM)
- Generowania i debugowania kodu (Codeforces ELO 2150)
- Analizy wizualnej — zdjęcia, wykresy, wireframe'y → kod
- Wielojęzycznych asystentów (140+ języków, kontekst kulturowy)
- Fine-tuningu pod domenę — Apache 2.0, pełna swoboda