GLM 4.7 Flash (Zhipu AI)
Najlepszy model klasy "local-friendly" 2026 roku. Uruchomiony lokalnie na sprzęcie Asus GX1 Ascent w kwantyzacji Q4. Model, który nie tylko generuje tekst — ale myśli, zanim odpowie.
Architektura MoE z Multi-Head Latent Attention
GLM-4.7-Flash to model typu MoE (Mixture-of-Experts) o łącznej liczbie 31,2 miliarda parametrów, z czego zaledwie 3 miliardy są aktywne podczas inferencji. Kluczową innowacją jest zastosowanie Multi-Head Latent Attention (MLA) — tej samej technologii uwagowej, którą stosuje DeepSeek. MLA kompresuje cache KV do ułamka standardowego rozmiaru, dzięki czemu pełne 128K kontekstu mieści się na pojedynczym GPU z 32 GB VRAM.
Preserved Thinking — rozumowanie między turami
W odróżnieniu od modeli, które wykonują Chain-of-Thought jednorazowo na początku, GLM-4.7 Flash stosuje Interleaved Thinking — przeplatane rozumowanie na każdym etapie odpowiedzi. Dodatkowo tryb Preserved Thinking zachowuje kontekst rozumowania między kolejnymi turami konwersacji. To krytyczne w zadaniach agentowych: model nie „zapomina" logiki z poprzedniego kroku, nawet po 20 turach dialogu.
Specjalistyczny Test Prawniczy
Model został poddany rygorystycznemu testowi, analizując 70-stronicową Ustawę o rynku kryptoaktywów z dn. 7 listopada 2025 r. (168 artykułów).
WYNIK TESTU: GLM-4.7 Flash bezbłędnie zinterpretował zawiłości prawne, cytował konkretne artykuły i nie uległ halucynacjom, pokonując w benchmarkach SWE-bench Verified modele takie jak Qwen3-30B czy GPT-OSS-20B.
Coding i zadania agentowe
GLM-4.7 Flash osiąga 59.2% na SWE-bench Verified — wynik, który deklasuje konkurencję w klasie modeli poniżej 30B aktywnych parametrów. Na τ²-Bench (wieloturowe zadania agentowe w retail i telekomunikacji) uzyskuje 79.5%, a na BrowseComp (autonomiczna nawigacja webowa) — 42.8%. To model stworzony do pracy jako lokalny agent kodujący: pisze kod, debuguje, iteruje i używa narzędzi.
Wdrożenie na DGX Spark / ASUS GX10
Dzięki architekturze MoE i MLA, model jest wyjątkowo lekki w inferencji. W kwantyzacji Q4 zajmuje ~18 GB pamięci — na naszych stacjach ze 128 GB zunifikowanego RAM-u działa z ogromnym zapasem. Kompatybilny z vLLM (z patchem MLA), SGLang, LM Studio i llama.cpp. API zgodne z formatem OpenAI — drop-in replacement dla GPT-4o-mini.
Licencja MIT — bez ograniczeń
GLM-4.7 Flash jest wydany na licencji MIT — najswobodniejszej licencji open-source. Pełna dowolność komercyjna, możliwość modyfikacji, fine-tuningu i redystrybucji. Zhipu AI udostępnia też darmowy tier API (1 concurrent request) i płatny FlashX (3 concurrent).
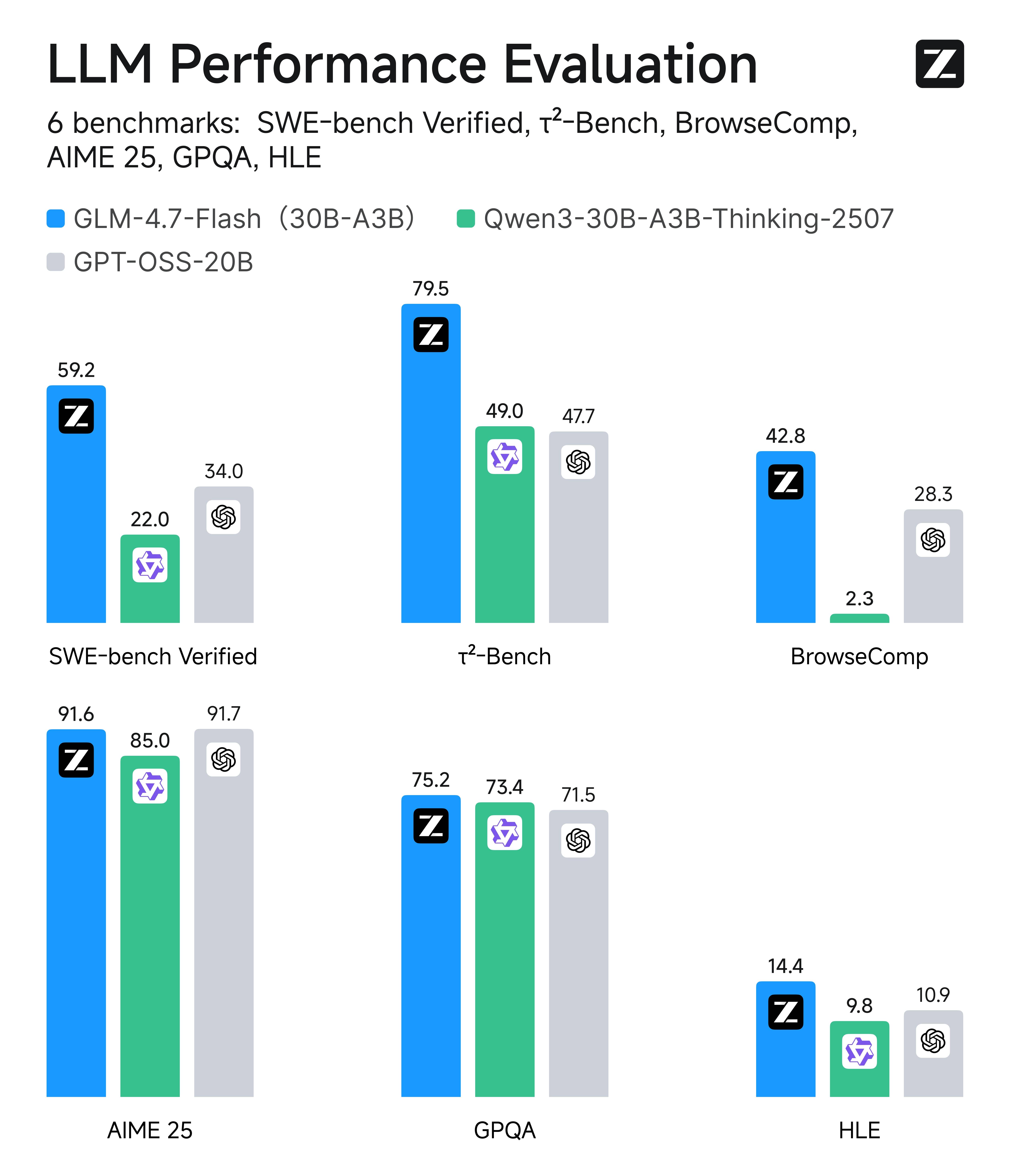
Wyniki benchmarków
Specyfikacja Techniczna
- Architektura: MoE (3B Active)
- Parametry łączne: 31.2B
- Attention: MLA (Multi-Head Latent)
- Context Window: 128K tokenów
- Max Output: 128K tokenów
- Thinking: Preserved / Interleaved
- Platforma Testowa: Asus GX1 Ascent
- Kwantyzacja: Q4_K_M (~18 GB)
- Frameworki: vLLM, SGLang, llama.cpp
- Licencja: MIT (pełna swoboda)
Idealny do:
- Analizy aktów prawnych, regulaminów, umów
- Lokalnych agentów kodujących (IDE, Cline, Roo Code)
- Wieloturowych chatbotów z zachowaniem kontekstu rozumowania
- Drop-in replacement dla GPT-4o-mini (API zgodne z OpenAI)