Llama 4 Scout
Pierwszy multimodalny model open-weight od Meta z architekturą Mixture-of-Experts. Scout został zaprojektowany jako kompaktowy, ale potężny agent — mieści się na pojedynczym GPU H100 przy kwantyzacji Int4.
Architektura MoE
Llama 4 Scout wykorzystuje architekturę Mixture-of-Experts z 16 ekspertami. Z 109 miliardów parametrów łącznych, w każdym kroku inferencji aktywnych jest tylko 17 miliardów — to sprawia, że model jest wyjątkowo wydajny obliczeniowo przy zachowaniu inteligencji znacznie większych modeli. Wytrenowany na ~40 bilionach tokenów danych multimodalnych.
10 milionów tokenów kontekstu
Najdłuższe okno kontekstowe wśród wszystkich dostępnych modeli open-weight. Scout przetrenowany jest z kontekstem 256K, a dzięki zaawansowanej generalizacji długości obsługuje do 10 milionów tokenów. To otwiera zupełnie nowe możliwości: podsumowania wielodokumentowe, analiza całych baz kodu, przetwarzanie obszernej historii aktywności użytkownika.
Natywna multimodalność
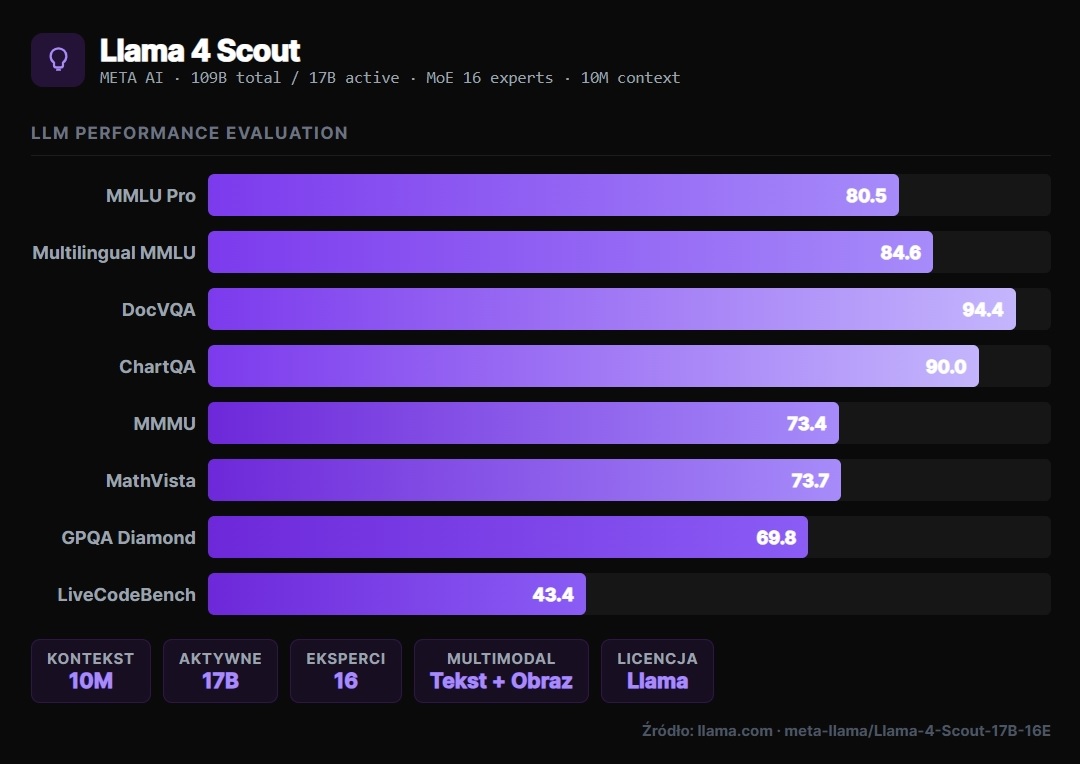
W odróżnieniu od poprzednich wersji Llama, Scout przetwarza tekst i obrazy natywnie (early fusion) — nie jest to dobudowany moduł wizyjny, lecz integralna część architektury modelu. Rozumie wykresy, dokumenty, tabele, faktury i screenshoty interfejsów. Osiąga 94.4% na DocVQA i 90.0% na ChartQA.
Wdrożenie na DGX Spark / ASUS GX10
Dzięki kwantyzacji Int4 (GGUF), model mieści się w 128 GB zunifikowanej pamięci naszych stacji roboczych. Aktywacja zaledwie 17B parametrów na token oznacza szybką inferencję nawet przy długich kontekstach. Function calling i tool-use działają out-of-the-box z kompatybilnymi frameworkami (vLLM, Ollama, llama.cpp).
Agenci i Function Calling
Scout został wytrenowany specjalnie pod kątem agentów autonomicznych. Posiada wbudowany mechanizm Chain-of-Thought, potrafi samodzielnie zdecydować, kiedy użyć kalkulatora, przeszukać bazę danych, czy wywołać zewnętrzne API. To nie jest „chatbot z pluginami" — to model, który rozumie jak planować i wykonywać wieloetapowe zadania.
Kluczowe benchmarki
0-shot, temp=0, bez majority voting. Źródło: meta-llama
Idealny do:
- Inteligentnych asystentów BOK z function calling
- Analizy dużych zbiorów dokumentów i faktur (RAG z 10M kontekstem)
- Autonomicznych agentów z obsługą narzędzi (SQL, API, kalkulatory)
- Analizy wizualnej — wykresy, screenshoty, dokumenty skanowane
- Wielojęzycznych wdrożeń (84.6% na Multilingual MMLU)
Scout vs. konkurencja
Scout przewyższa Flash-Lite w rozumieniu dokumentów (DocVQA 94.4 vs 89.2) i w długim kontekście (10M vs 1M). Flash-Lite ma przewagę w czystej szybkości inferencji jako model zamknięty.
Scout wygrywa na wszystkich benchmarkach multimodalnych i oferuje 78× dłuższy kontekst (10M vs 128K). Mistral zachowuje przewagę w szybkości na czystych zadaniach tekstowych.
Scout przewyższa Llama 3.3 w matematyce (MATH 90% vs 77.8%) i multimodalności (brak w 3.3). Llama 3.3 wciąż lekko lepsza w SWE-bench (+4 pkt) jako model dense.