Qwen 3.6
Dwa warianty od Alibaba, jedna rodzina. 27B Dense — flagowy coding, który pokonuje modele 15× większe. 35B-A3B MoE — 3-5× szybsza inferencja przy niewiele niższej jakości. Oba z 256K kontekstem, multimodalnością i licencją Apache 2.0.
27B Dense
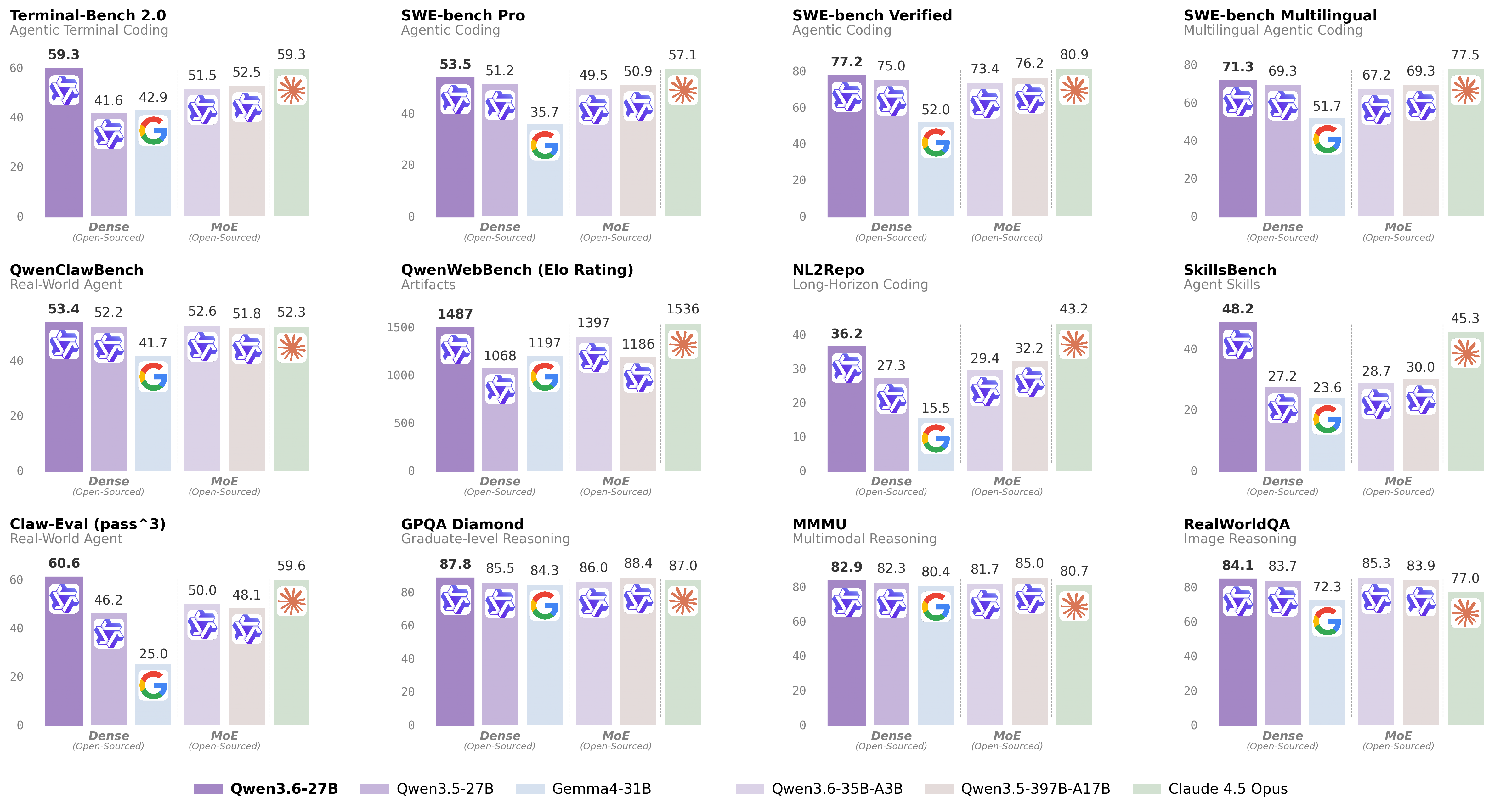
Wszystkie parametry aktywneFlagowy model kodujący Alibaba. Wszystkie 27 miliardów parametrów pracuje przy każdym tokenie — żadnego routingu, żadnych śpiących ekspertów. Wynik? 77.2% na SWE-bench Verified, 59.3 na Terminal-Bench (na równi z Claude 4.5 Opus) i pokonanie poprzedniego flagowca Qwen3.5-397B-A17B na każdym benchmarku kodowania. Model 27B, który bije model 397B — to nie literówka.
35B-A3B MoE
Tylko 3B aktywnych / tokenWariant Mixture-of-Experts: 35 miliardów parametrów łącznie, ale tylko 3 miliardy aktywne przy każdym tokenie. Efekt? 3-5× szybsza inferencja niż 27B Dense na tym samym sprzęcie. Społeczność raportuje ~120 tok/s na RTX 4090, ~101 tok/s na RTX 3090 w Q4. Idealny do RAG, długich kontekstów i szybkich interakcji.
Porównanie benchmarków — 27B Dense vs 35B-A3B MoE
Wspólne cechy obu wariantów
27B pokonuje 397B
To najbardziej zaskakujący wynik w otwartych modelach 2026 roku. Qwen3.6-27B Dense — model z zaledwie 27 miliardami parametrów — pokonuje na każdym benchmarku kodowania poprzedniego flagowca Qwen3.5-397B-A17B, który ma 397 miliardów parametrów łącznie (17B aktywnych). SWE-bench Verified: 77.2 vs 76.2. Terminal-Bench: 59.3 vs 52.5. SkillsBench: 48.2 vs 30.0. Model 15× mniejszy, a wyniki lepsze. Architektura dense (bez routingu MoE) oznacza też prostsze wdrożenie i bardziej przewidywalne zachowanie.
35B-A3B — prędkość jest cechą
Wariant MoE aktywuje tylko 3B z 35B parametrów — ale to wystarcza, by generować tokeny 3-5× szybciej niż model dense na identycznym sprzęcie. Na RTX 4090 w Q4 to ~120 tok/s — tekst pojawia się natychmiast. Idealny do interaktywnych asystentów, gdzie użytkownik czeka na odpowiedź. Jakość jest niższa niż 27B na najtrudniejszych zadaniach kodowania, ale na codziennych zadaniach — RAG, refactoring, generowanie kodu, konwersacja — różnica jest minimalna.
Gated DeltaNet — hybrydowa uwaga
Oba warianty stosują hybrydową architekturę uwagową: 3 warstwy Gated DeltaNet (liniowa uwaga) na każdą 1 warstwę klasycznego global attention. DeltaNet nie doświadcza spadku wydajności powyżej 64K tokenów — dlatego oba modele natywnie obsługują 256K kontekst (z rozszerzeniem do 1M) bez trików z RoPE scaling. Tryb Preserved Thinking zachowuje łańcuch rozumowania między turami konwersacji.
Wdrożenie na DGX Spark / ASUS GX10
Na naszych stacjach ze 128 GB zunifikowanej pamięci oba warianty mieszczą się z ogromnym zapasem. 27B Dense zajmuje ~17 GB w Q4, 35B-A3B ~21 GB. Możliwe jest uruchomienie obu wariantów jednocześnie i przełączanie się między nimi zależnie od zadania — 27B do trudnych problemów kodowania, 35B-A3B do szybkich interakcji z użytkownikami. API zgodne z OpenAI — drop-in replacement.
Który wariant wybrać?
Wybierz 27B Dense gdy:
- • Priorytetem jest jakość kodu
- • Budujesz agenta kodującego
- • Rozwiązujesz złożone problemy logiczne
- • Potrzebujesz multilingualnego kodowania
Wybierz 35B-A3B gdy:
- • Priorytetem jest szybkość odpowiedzi
- • Obsługujesz wielu użytkowników
- • Pracujesz z RAG i długimi kontekstami
- • Chcesz niższe koszty obliczeniowe
Oba warianty Qwen 3.6 dostępne do wdrożenia
Pomożemy dobrać wariant do Twoich potrzeb, skonfigurować środowisko i zintegrować z istniejącą infrastrukturą. Oba modele działają na DGX Spark i ASUS GX10.
Skontaktuj się z nami